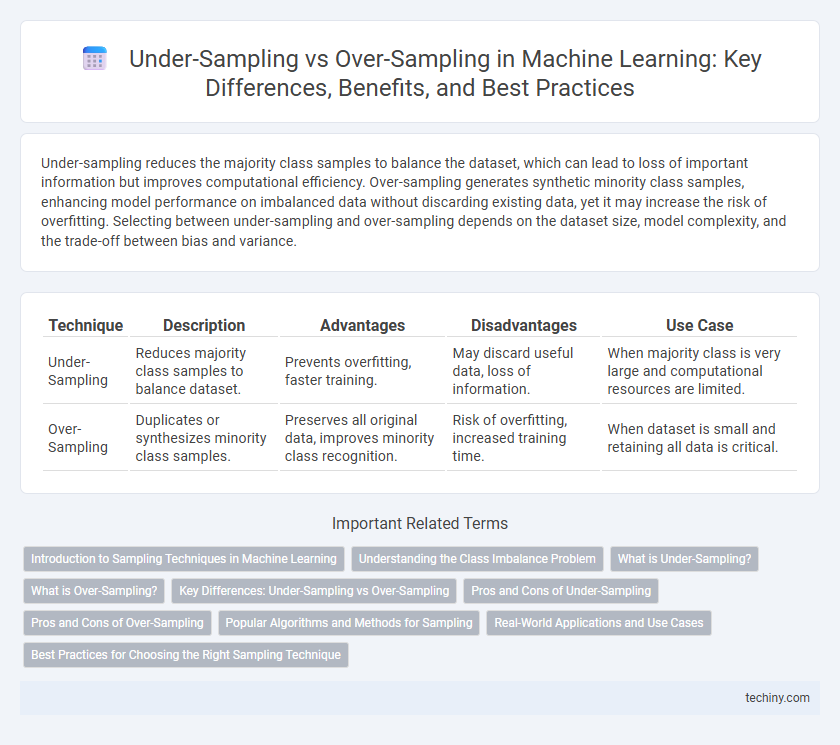
Under-sampling reduces the majority class samples to balance the dataset, which can lead to loss of important information but improves computational efficiency. Over-sampling generates synthetic minority class samples, enhancing model performance on imbalanced data without discarding existing data, yet it may increase the risk of overfitting. Selecting between under-sampling and over-sampling depends on the dataset size, model complexity, and the trade-off between bias and variance.
Table of Comparison
| Technique | Description | Advantages | Disadvantages | Use Case |
|---|---|---|---|---|
| Under-Sampling | Reduces majority class samples to balance dataset. | Prevents overfitting, faster training. | May discard useful data, loss of information. | When majority class is very large and computational resources are limited. |
| Over-Sampling | Duplicates or synthesizes minority class samples. | Preserves all original data, improves minority class recognition. | Risk of overfitting, increased training time. | When dataset is small and retaining all data is critical. |
Introduction to Sampling Techniques in Machine Learning
Under-sampling and over-sampling are essential techniques to address class imbalance in machine learning datasets. Under-sampling reduces the majority class size to balance the data, while over-sampling generates synthetic samples or duplicates minority class instances to increase their representation. Proper application of these sampling methods improves model performance by preventing bias towards the majority class and enhancing generalization.
Understanding the Class Imbalance Problem
Class imbalance occurs when the number of instances in one class significantly outnumbers those in other classes, leading to biased machine learning models. Under-sampling reduces the majority class by removing samples to balance the dataset, which may risk losing important information. Over-sampling increases the minority class by duplicating or generating synthetic samples such as SMOTE, helping models learn better decision boundaries without discarding existing data.
What is Under-Sampling?
Under-sampling is a technique used in machine learning to address class imbalance by reducing the number of majority class samples. This method helps improve model performance by balancing datasets, preventing bias towards the majority class, and enhancing the detection of minority class patterns. Common under-sampling methods include random under-sampling and cluster-based under-sampling, which selectively remove redundant or less informative majority class instances.
What is Over-Sampling?
Over-sampling is a technique used in machine learning to address class imbalance by increasing the number of instances in the minority class. This method duplicates existing minority class samples or synthetically generates new data points using algorithms like SMOTE (Synthetic Minority Over-sampling Technique). Over-sampling improves model performance by enabling better generalization and reducing bias towards the majority class during training.
Key Differences: Under-Sampling vs Over-Sampling
Under-sampling reduces the size of the majority class to balance datasets, which can lead to loss of potentially valuable information, while over-sampling increases the minority class samples using techniques like SMOTE to avoid data loss but may introduce overfitting. Under-sampling is preferable when the dataset is large and imbalance is severe, whereas over-sampling suits smaller datasets where preserving all original data is critical. Both methods aim to improve model performance on imbalanced classification tasks by addressing class distribution disparities.
Pros and Cons of Under-Sampling
Under-sampling reduces the size of the majority class to address class imbalance, which helps improve model training time and reduces bias towards the majority class. However, it risks losing valuable information and can cause underfitting due to the removal of potentially important data points. This technique is most effective when the dataset is large enough to maintain representative samples after down-sampling the majority class.
Pros and Cons of Over-Sampling
Over-sampling techniques replicate minority class samples to address class imbalance, enhancing model performance on underrepresented data. This method reduces bias towards the majority class but can lead to overfitting due to duplicate data points. Computational cost increases as the dataset size grows, impacting training efficiency and resource usage.
Popular Algorithms and Methods for Sampling
Random Under-Sampling (RUS) and Synthetic Minority Over-sampling Technique (SMOTE) are among the most popular algorithms for addressing class imbalance in machine learning datasets. RUS reduces the majority class by randomly removing samples, thereby simplifying the data distribution, while SMOTE generates synthetic examples for the minority class by interpolating between existing minority samples to enhance model learning. Techniques like Adaptive Synthetic Sampling (ADASYN) and NearMiss further refine sampling by focusing on difficult-to-classify instances or generating more representative minority examples.
Real-World Applications and Use Cases
Under-sampling is widely applied in fraud detection systems where reducing the majority class prevents model bias towards non-fraudulent transactions, ensuring efficient anomaly identification. Over-sampling techniques, such as SMOTE, are prevalent in medical diagnosis datasets with rare diseases, enhancing minority class representation to improve classification accuracy. Both methods are crucial in customer churn prediction, balancing dataset classes to optimize predictive performance and support retention strategies.
Best Practices for Choosing the Right Sampling Technique
Selecting the appropriate sampling technique depends on the dataset's class imbalance severity and the model's sensitivity to minority class underrepresentation. Under-sampling reduces the majority class size to balance classes but risks losing valuable information, making it suitable for large datasets with significant imbalance. Over-sampling duplicates or synthetically generates minority class samples, preserving data completeness and improving minority class learning, especially in smaller datasets with moderate imbalance.
Under-Sampling vs Over-Sampling Infographic